競技プログラミングをしていると、グラフ理論をきちんと理解していないと、計算時間がかかってしまい、正解できないケースが散見された。
私は情報学科出身ではないため、きちんとした理論は理解してない。そのため、どうしても超えられない壁が存在していたために、これを期にきちんと理解をしたいと考え始めるようになった。
今回はよく出てくるグラフ理論だ。
グラフ理論とは、「もののつながり」を点と線で表す考え方となる。
例えば、都市と都市をつなぐ道路、駅と駅をつなぐ電車、友達同士の関係などは、すべて「つながり」として考えることができる。このとき、都市や駅、人物などを「点(頂点)」として、つながっている関係を「線(辺)」で表す。線に向きがある場合(AからBへなど)は「有向グラフ」、向きがない場合は「無向グラフ」と呼ぶ。また、線に距離や時間などの数値がつくと「重み付きグラフ」と言います。
例えば、以下の問題を解くことができる
- 地図 → 道路の最短ルートを探す
- SNS → 誰が誰とつながっているかを分析
- 作業工程 → どの順番で進めればよいか整理
このように、グラフ理論は複雑な関係や構造を整理し、効率的に分析するための道具となる。
今回は、グラフ理論の探索で使われるDFS / BFS に付いて簡単に書いていきたい。
DFS / BFS
DFS(深さ優先探索)とBFS(幅優先探索)は、グラフやツリーを探索する基本的なアルゴリズム。
DFS(Depth-First Search:深さ優先探索)
特徴
- とにかく深く潜ってから戻る
- スタック(stack)を使うイメージ(Pythonでは再帰でもOK)
- 探索の道を1本決めて、その先をどんどん進む
流れ
今のノード → 隣のノード → さらにその隣 → …(戻る)→ 別の隣へ → …例(1→2→3→4→…のように潜る)
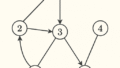
グラフ構造:
1 - 2 - 3
| |
4-------5
DFS(1):
1 → 2 → 3 → 5 → 4(深く行ってから戻る)BFS(Breadth-First Search:幅優先探索)
特徴
- 近い順に調べていく
- キュー(queue)を使う
- 最初に発見したノードの「次に近いノード」から順に調査
流れ
今のノード → 近い隣 → さらにその隣 …(層を広げていく)例(近い順にまんべんなく)
グラフ構造:
1 - 2 - 3
| |
4-------5
BFS(1):
1 → 2 → 4 → 3 → 5(近い順に広がっていく)Pythonでの簡単な比較コード
上記の説明だけでは、分かりにくいので以下のサンプルで理解するほうがいいだろう。
from collections import deque
graph = {
1: [2, 4],
2: [1, 3],
3: [2, 5],
4: [1, 5],
5: [3, 4]
}
def dfs(start):
visited = set()
result = []
def _dfs(v):
visited.add(v)
result.append(v)
for neighbor in graph[v]:
if neighbor not in visited:
_dfs(neighbor)
_dfs(start)
return result
def bfs(start):
visited = set()
queue = deque([start])
result = []
while queue:
v = queue.popleft()
if v not in visited:
visited.add(v)
result.append(v)
queue.extend(graph[v])
return result
print("DFS:", dfs(1)) # 深く潜る
print("BFS:", bfs(1)) # 広く探す上記を実行すると、結果は以下の通りになる。
DFS: [1, 2, 3, 5, 4]
BFS: [1, 2, 4, 3, 5]上記を見れば分かる通り、DFSは、リンク先をどんどん探していく。全て訪問したら、対象外にしていく方法だ。一方で、BFSは、隣同士のノードをどんどんqueに追加して探索してく方法だ。
上記のプログラムか、探索のテンプレートになるので、丸ごと覚えてもいいかもしれない。

コメント